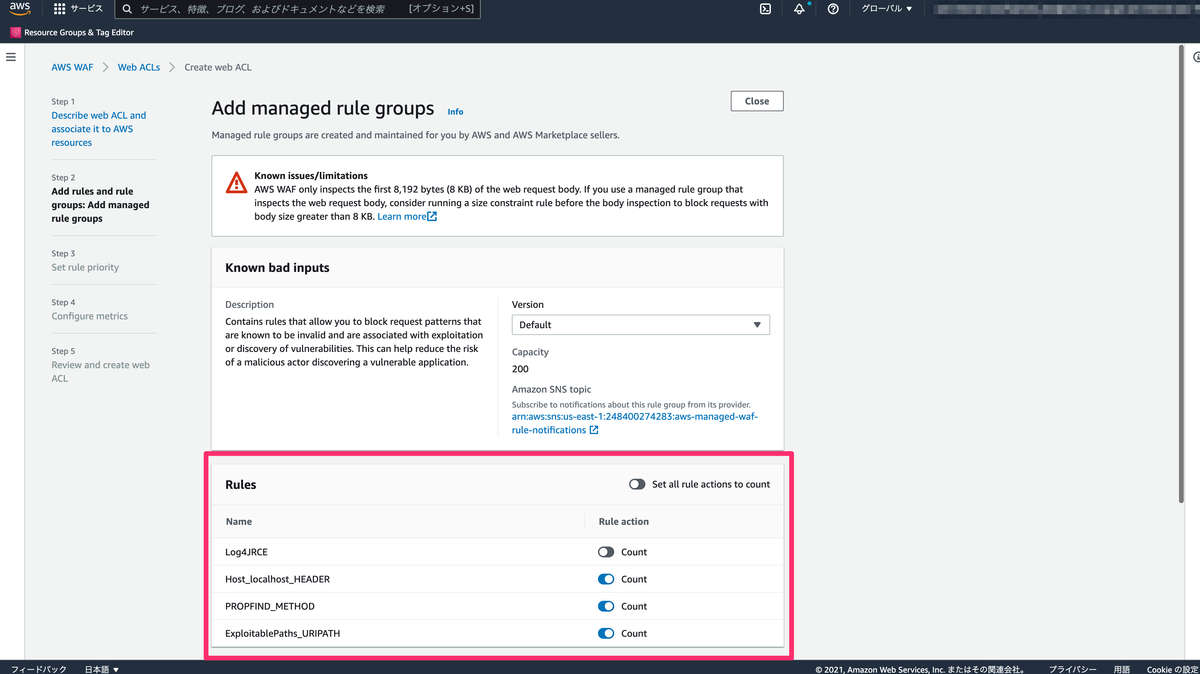
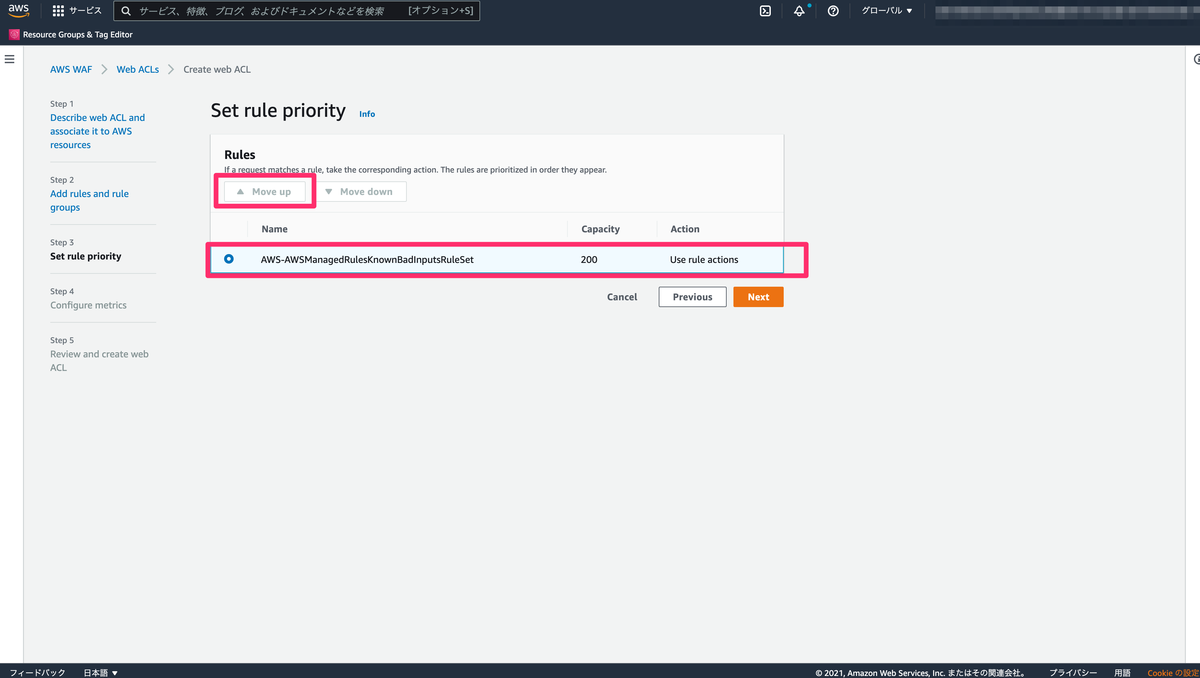
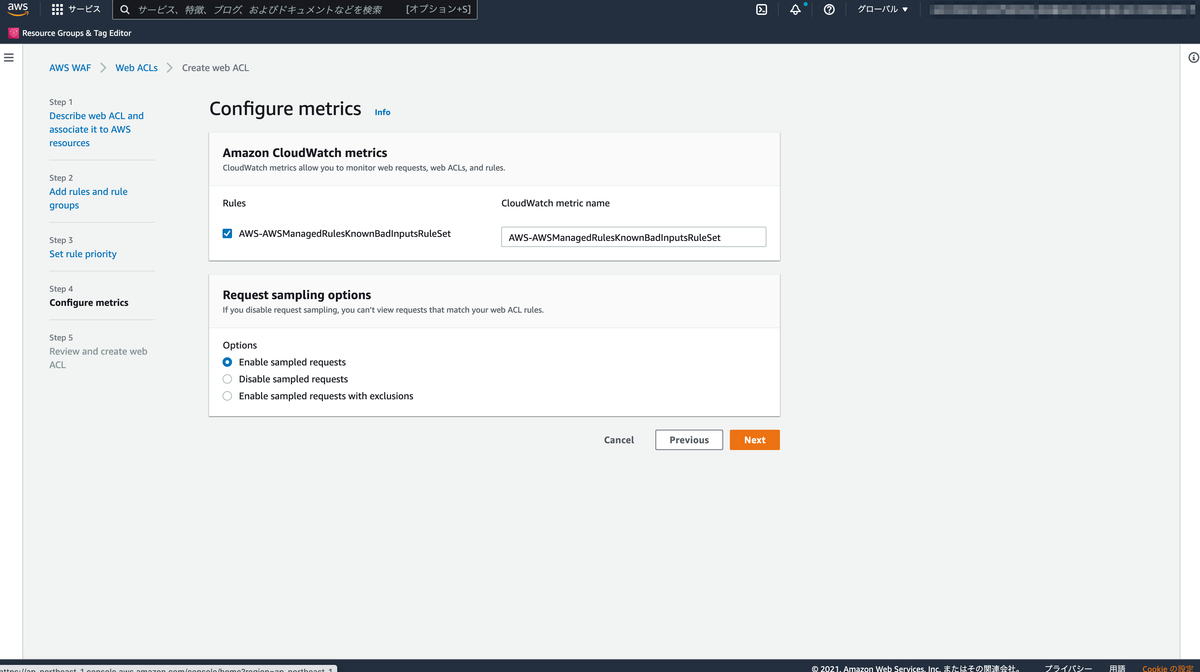
はじめに
こんにちは。
普段は新規開発メインの会社で SRE やデータエンジニアをしているものです。
クラウドプラットフォームとしては AWS や GCP をメインで利用していますが、最近 Azure OpenAI の API が利用可能になったことで Azure も使い始めました。
そこで様々なエンジニアが Azure 上でオペレーションを行うことが想定されるため、Resource Groupや IAM、OpenAI などを包括的に管理したいです。
そのための設計と、上記リソースなどを Terraformで IaC する方法を今回ご紹介します。
ちなみに、ワークロードには Azure Pipeline を採用しました。理由は後述します。
それでは参りましょう。
前提
Azure DevOps
Azure DevOps とはアプリケーション開発を円滑に行うためのサービスの集合体です。具体的には Git リポジトリの Azure Repos や、CI/CD サービスの Azure Pipeline などです。
初学者で間違えがちですが、Azure DevOps は Azure とは別プラットフォームです。
ですので、ユーザーの権限管理の考え方や、管理単位までほとんどが異なりますので注意しましょう。
ただ Azure Active Directory (以後 AD) と接続して、ユーザー管理を簡素化することはできます。これについては別記事にしようと思います。
今回 ワークロードに Azure Pipeline を採用した理由としては、最もセキュアな環境が構築できるからです。
私の環境では、Github Actions、Cloud Build、AWS CodePipeline など様々な環境が存在しますが、環境構築を行う際の認証資格はほぼなんでも作成、削除できる権限を持つため、サービスプリンシパルを作成して、そのシークレットを他の環境へ保存することはセキュリティリスクが高いです。
Azure Pipeline ではサービス接続という機能でサービスプリンシパルの自動作成ができることから、シークレット自体は発行されますが、その値をクライアント側で確認することはできず、特に持ち出す必要もありません。
ちなみにここで、Managed ID を使えばいいのでは?と思った方がいるかと思いますが、Azure Pipeline ではユーザー管理のVMでエージェントを動かす場合を除いて、Managed ID は使えません。
ですので、上記の方法を取ります。
具体的には後述します。
Terraform
ここで特筆することは無いかもしれません。
Azure リソースを作成するためのプロバイダーが用意されており、ほぼすべてのリソース作成が可能だと思います。 https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs
IAM
Azure では Subscription 以下のリソースにも IAM で権限を付与することができます。
この際、上層のIAMを引き継ぐ形で、それに追加して下層で権限を付与できます。
ここでほかのクラウドプラットフォームと異なるのは
「大きく権限を付与して、拒否で権限を絞っていくのではなく、各レイヤーで細かく権限を付与していく」
ということです。 つまり、Azure での IAM の考え方は引き算です。
実際に現時点でも IAM で拒否ルールは作成できますが、Blueprints 経由で作成されたもののみが対象です。つまり今回のように Terraform で作成した場合対象外です。

以下の様に、Resource Group でもIAMの設定ができることがわかります。
上層で定義されているものは (継承済み) と表示されます。この Resource Group は属する Subscription の権限を継承していることがわかります。

そして、もう一点重要なのが、上層でつけられた権限を下層で拒否することはできないことです。
例えば、Subscription で所有者の権限を付与して、Resource Group で閲覧者の権限を付与した場合、Subscription に属するリソースの範囲全てで所有者の権限が適用されます。
つまりロール付与は上書き拒否できないのです。
例えば以下のようなロールの jsonを仮定した場合、
{
"id": "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx/providers/Microsoft.Authorization/roleDefinitions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"properties": {
"roleName": "test-role",
"description": "test権限",
"assignableScopes": [
"/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx/resourceGroups/test-resource-group"
],
"permissions": [
{
"actions": [
"*"
],
"notActions": [
"Microsoft.Resources/subscriptions/resourceGroups/delete",
"Microsoft.Storage/storageAccounts/delete"
],
"dataActions": [],
"notDataActions": []
}
]
}
}
Subscription で所有者の権限を付与している場合、上記 json の scope では Resource Group を指定していて、notActions で Resource Group、Storage Account の削除を指定してるのでそのアクションができないと思いがちですが、それは間違いです。
先程述べた通り、上層の権限を上書き拒否するのはできないのと、notActions の本来の意味は、actions で許可したアクションを拒否することなので、他のロールと関係を持ちません。
以上のことに注意しましょう。
手順
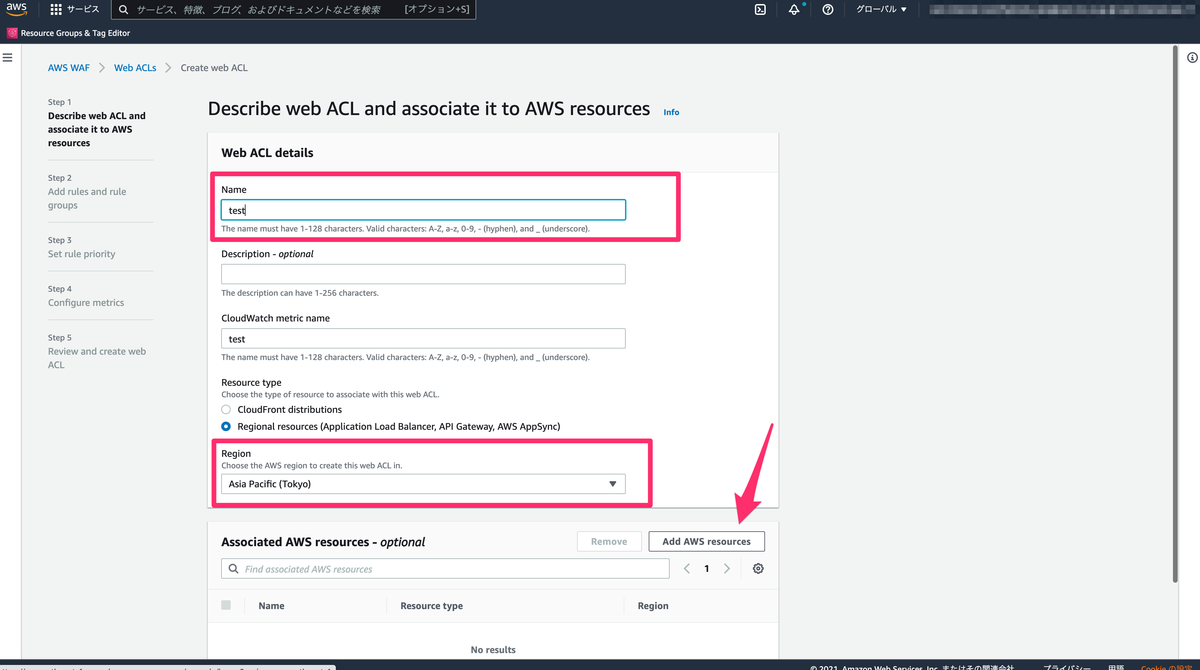
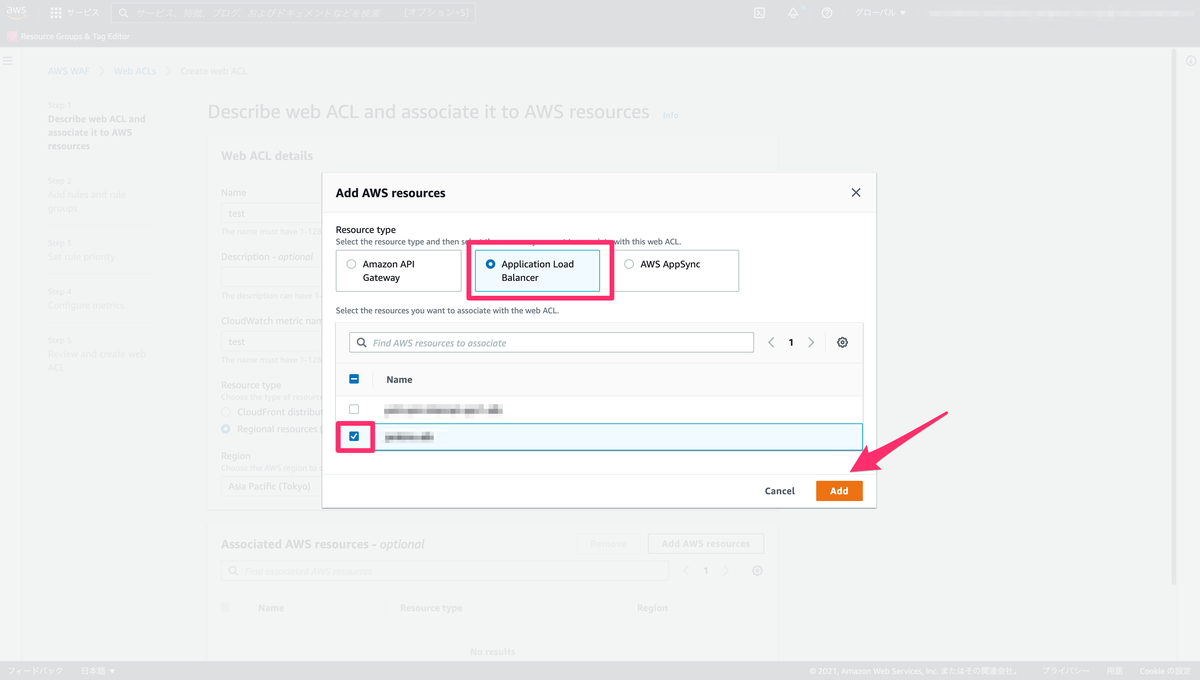
それでは実際に Terraformの環境を構築して、Azure リソースを作成していきましょう。
今回作成するリソースはこちらです
・Resource Group
・Storage Account (Terraform Backend 用)
・Blob コンテナ
・IAM カスタムロール
・IAM ロールアサインメント
・Azure Open AI
Terraform ファイル
手元では Terraform の環境が整っている前提で話を進めます。 今回は Backend に Storage Blob を採用するので、はじめは local でリソースを作成しましょう。
以下のようなディレクトリ構成でファイルを用意します。
/terraform/test /terraform/test/resource_group.tf /terraform/test/storage.tf /terraform/test/iam.tf /terraform/test/cognitive_service.tf /terraform/test/provider.tf /terraform/test/terraform.tf
resource_group.tf
resource "azurerm_resource_group" "tf" {
name = "tf-resource-group"
location = "Japan East"
}
resource "azurerm_resource_group" "this" {
name = "resource-group"
location = "Japan East"
}
storage.tf
resource "azurerm_storage_account" "this" {
name = "tfenv"
resource_group_name = azurerm_resource_group.tf.name
location = azurerm_resource_group.tf.location
account_tier = "Standard"
account_replication_type = "GRS"
account_kind = "StorageV2"
## tfstateを保存するのでバージョニングは必須
blob_properties {
versioning_enabled = "true"
}
}
resource "azurerm_storage_container" "tfstate" {
name = "tfstate"
storage_account_name = azurerm_storage_account.this.name
container_access_type = "private"
}
iam.tf
前提で書いたことに注意しましょう。
ここでは Subscription レベルに設定します。
resource "azurerm_role_definition" "this" {
name = "test-role"
scope = "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx"
description = "test権限"
permissions {
actions = [
"*"
]
not_actions = [
"Microsoft.Authorization/*/Delete",
"Microsoft.Authorization/*/Write",
"Microsoft.Authorization/elevateAccess/Action",
"Microsoft.Blueprint/blueprintAssignments/write",
"Microsoft.Blueprint/blueprintAssignments/delete",
"Microsoft.Compute/galleries/share/action",
# リソースグループ削除
"Microsoft.Resources/subscriptions/resourceGroups/delete",
# リソースグループ作成
"Microsoft.Resources/subscriptions/resourceGroups/write",
]
}
}
resource "azurerm_role_assignment" "this" {
principal_id = xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx
role_definition_id = azurerm_role_definition.this.role_definition_resource_id
scope = "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx"
}
cognitive_service.tf
resource "azurerm_cognitive_account" "openai" {
custom_subdomain_name = "test"
kind = "OpenAI"
location = "eastus"
name = "test"
resource_group_name = azurerm_resource_group.this.name
sku_name = "S0"
network_acls {
default_action = "Allow"
}
depends_on = [
azurerm_resource_group.this,
]
}
resource "azurerm_cognitive_deployment" "gpt_35_turbo" {
cognitive_account_id = azurerm_cognitive_account.openai.id
name = "gpt-35-turbo"
model {
format = "OpenAI"
name = "gpt-35-turbo"
version = "0301"
}
scale {
type = "Standard"
}
depends_on = [
azurerm_cognitive_account.openai,
]
}
provider.tf
provider "azurerm" {
features {}
}
terraform.tf
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~> 3.62.1"
}
}
backend "local" {
path = "test.tfstate"
}
}
Terraform 実行
実際にリソースを作成していきましょう。
はじめローカルで作成するのは、tfstate 用の Resource Group と Storage Account、Blob コンテナのみで大丈夫です。
手元の環境では az cli が使える前提です。
ローカルとazureの認証 $ az login 向いているサブスクリプション、資格情報を取得 $ az account show 対象のサブスクリプションを向いていない場合は切り替える $ az account set --subscription "サブスクリプションIDまたはサブスクリプション名"
terraform/test ディレクトリに移動し、以下を実行
$ terraform init $ terraform plan $ terraform apply -auto-approve
これにより、ローカルからオペレーションを実行し、Azure リソースを作成するのに成功しました。
実際に作成されているかを確認してください。
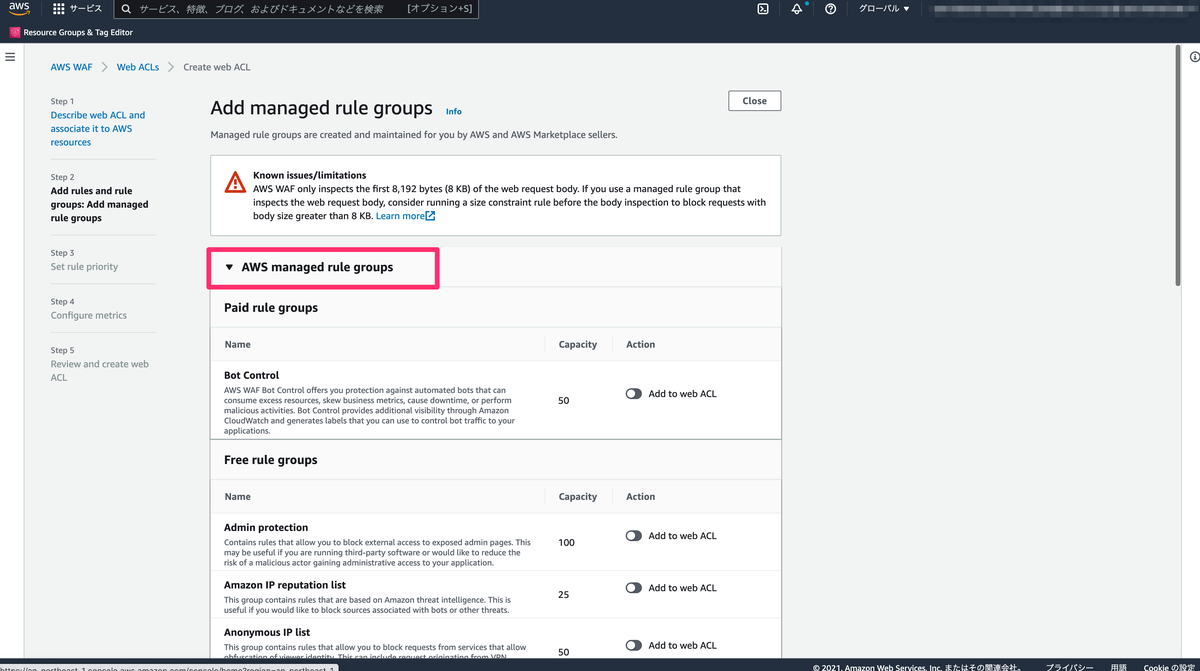
Azure Pipeline 環境構築
Azure Pipeline 環境を構築するにあたって、Azure DevOps Organization と Azure DevOps Project を作成しましょう。
Azure DevOps 自体が Azure とは別プラットフォームになるため、ユーザーの権限管理も独特です。
そちらについては別記事にします。
作成した Project の画面からPipelineを作成します。

コードは GitHub を指定して、適宜 GitHub 認証をしてください。 途中、pipeline の yaml テンプレートを求められますが、一旦無視をして保存してください。
作成できたら細かい設定をしていきます。
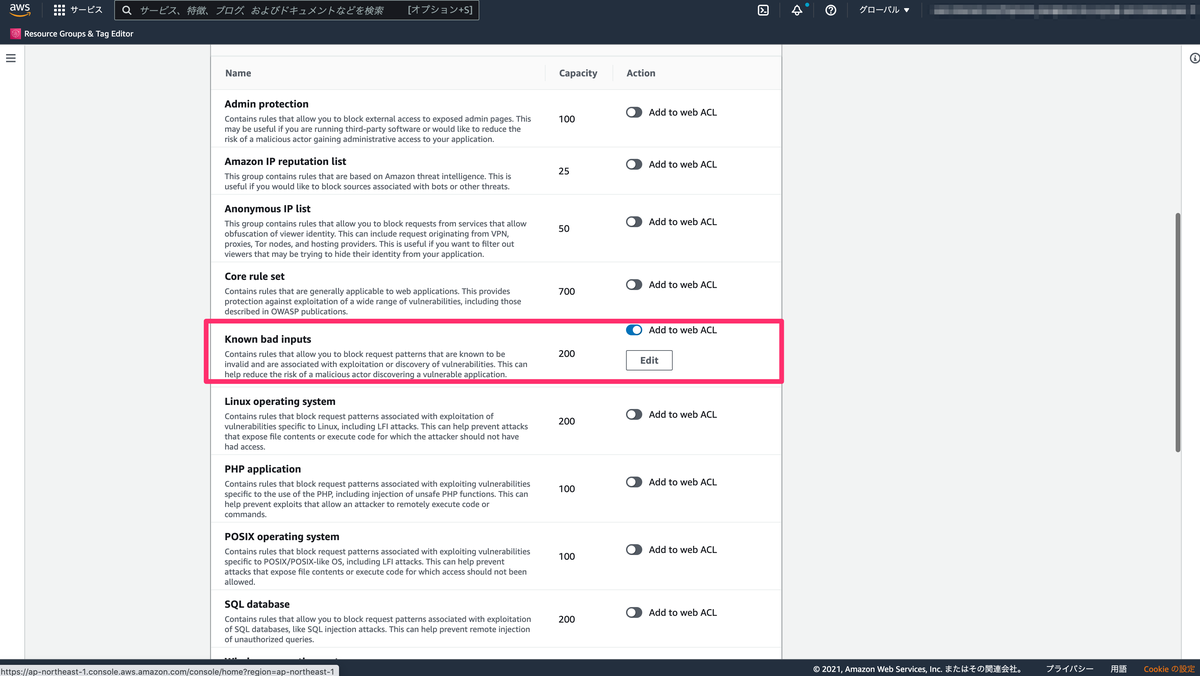
作成された pipeline を選択し、Edit を選択

右上から、Trigger を選択

まずは pipeline の yaml からです。

今回対象のリポジトリの任意の場所に以下のような yaml ファイルを配置し、YAML file path にその場所を指定します。 詳細については Azure DevOps 公式ドキュメントを御覧ください。
pipeline 内で使用する環境変数などは variables で設定しましょう。variables group を設定した場合はデフォルトで 実行環境 にexport されています。
jobs:
- job: terraform
pool:
vmImage: ubuntu-latest
workspace:
clean: all
variables:
- group: test-variables
steps:
- task: ms-devlabs.custom-terraform-tasks.custom-terraform-installer-task.TerraformInstaller@1
displayName: install terraform
inputs:
terraformVersion: latest
- task: TerraformCLI@0
displayName: terraform init
inputs:
command: init
# サービス接続名
backendServiceArm: test connection
workingDirectory: /terraform/test
backendType: azurerm
- task: TerraformCLI@0
displayName: terraform format
inputs:
command: fmt
commandOptions: -recursive
workingDirectory: /terraform/test
- task: TerraformCLI@0
displayName: terraform validate
inputs:
command: validate
# サービス接続名
environmentServiceName: test connection
commandOptions: -no-color
workingDirectory: /terraform/test
- task: TerraformCLI@0
displayName: terraform plan
continueOnError: true
inputs:
command: plan
# サービス接続名
environmentServiceName: test connection
commandOptions: -no-color -out=tfplan"
workingDirectory: /terraform/test
runAzLogin: true
- task: TerraformCLI@0
displayName: terraform apply
inputs:
command: apply
# サービス接続名
environmentServiceName: test connection
commandOptions: -no-color -auto-approve"
workingDirectory: /terraform/test
runAzLogin: true
task には自身で script を定義することもできますし、market place で定義されている task を利用することもできます。
今回は便利ですので、以下のような extensions を利用しています。
https://marketplace.visualstudio.com/items?itemName=charleszipp.azure-pipelines-tasks-terraform
https://marketplace.visualstudio.com/items?itemName=ms-devlabs.custom-terraform-tasks
extensions の設定は Organization Settings の以下の箇所から行います。

話は pipeline の設定に戻って、次は Get Sourcesです。
Authorized using connection で設定した方法で pipeline と GitHub が接続されます。

接続方法には、GitHub Apps か OAuth の大きく2つの認証方式がありますが、GitHub Apps を利用する際は注意が必要です。
公式ドキュメントにも書いてありますが、1リポジトリにつき、1 Organization でしか利用できません。
ですので、他の Organization でも同じリポジトリに対して pipeline を作成する際は OAuth を利用して認証しましょう。
設定の詳細は Project Settings の Service connections から確認しましょう。
OAuthの場合、GitHub ユーザーは対象のリポジトリに対して「Write」権限を持っていれば十分です。

次に Variables です。
yaml では定義していますが、別途定義が必要なものはここで定義しましょう。

もし Variables group を設定したい場合は、Pipelines の Library から設定してください。
ここでは Pipeline permissons が設定でき、この Variables Group へのアクセス許可をしないと参照でエラーが出ることに注意してください。

最後に Triggers です。
Trigger は2種類設定ができ、
・CI (ブランチへのコミットにより発火)
・PR (プルリクにより発火)
どちらとも ON/OFF、yaml で設定した場合は Override できます。

最後に Save を押し、保存を忘れずにしてください。
次に先程 yaml で設定したサービス接続の設定をしましょう。
これにより、pipeline から Azure にアクセスでき、リソースを作成することができます。
前提でも書きましたが、今回はマネージドな環境を利用しているため、サービスプリンシパルを作成し、その資格情報を用いて認証します。
Managed Identity はユーザー管理のVM で pipeline agent を動かす場合に限り設定できるため、今回は対象外です。


ここでは Auto を選択することをおすすめします。
Auto では自動でサービスプリンシパルが作成され、シークレットをユーザー側で確認、持ち出すことはできません。
特にここでのサービスプリンシパルには「共同作成者」の権限を付与するため、漏れた際のリスクが大きすぎます。
これにより、よりセキュアな環境が実現されます。
作成されたサービスプリンシパルを選択し、「Managed Service Principal」を押すと、Azure AD のアプリ登録の画面に遷移するので、このサービスプリンシパルのIDを確認しましょう。
そして、今回リソースを作成する対象の Subscription の IAM でこのサービスプリンシパルに「共同作成者」の権限を付与します。

これで設定は完了です。 先程の terraform テンプレートをコミットなり PR なり作成して、pipeline を動かしましょう。
おわりに
同じベンダーが開発したサービスを利用すると、よりセキュアな環境で開発ができます。
パフォーマンスや使い勝手などはまだわかっていない部分ですが、今のところ不満は無いです。
OpenAI や Face API など Azure には魅力的な AI サービスが豊富にありますので、この際利用してみてはいかがでしょうか。
その際、環境構築に本記事が役立てば幸いです。