はじめに
こんにちは。
普段は新規開発メインの会社で SRE やデータエンジニアをしているものです。
クラウドプラットフォームとしては AWS や GCP をメインで利用していますが、最近 Azure OpenAI の API が利用可能になったことで Azure も使い始めました。
マルチプラットフォームなアーキテクチャを取っていますが、今後 Azure 内での様々なサービスの利用、リソースの作成が予想されるため、セキュリティや障害対応を考えて証跡ログの調査方法を確立させます。
みなさんがよく利用されている AWS で例えて言うと、CloudTrail の証跡ログを S3 にエクスポートし、そのバケット内のオブジェクトを Athena で分析するイメージです。
Azure の基礎知識
以降で出てくる内容、用語をスムーズに理解するために、まず基礎知識を説明します。
ChatGPT のほうが私よりも賢いので、聞いてみることもおすすめします。
・Azure AD
Microsoft Azureを利用するための管理単位です。
会社単位で作ることをおすすめします。
Microsoft アカウントを使って作成し、Azure AD 内で組織ユーザを作り、その組織ユーザーを使って Azure 内にリソースを作成していきます。
Microsoft アカウントを使ってあれこれすることはおすすめしません。
・サブスクリプション
課金の単位です。
Azure AD 内で言うと最上位概念です。
すべてのリソースは後述するリソースグループに含まれ、そのリソースグループは1つのサブスクリプションと結び付けられている必要があります。
サブスクリプションの IAM で組織ユーザーに権限を付与することで、リソースグループ以降は権限を継承することができます。
サブスクリプションには以降の Activity Log はすべて表示されるため、本記事ではこちらを対象にします。
・リソースグループ
Azure 内でのリソースを管理する単位です。
できることは主に以下です。
・統一管理: リソースグループ内のリソースに対して一元的にアクセス制御、監視、およびアラート設定を行える。
・共通タグ付け
・リソースの展開: Azure Resource Manager テンプレートを使用して、リソースグループ内に複数のリソースを一度に展開できる。
・リソースの移動: リソースを他のリソースグループやサブスクリプションに移動することができる。
・コンプライアンスとポリシー: Azure Policy を使用して、リソースグループ内のリソースに対してポリシーを適用し、コンプライアンスを確保できる。
・リソースの構成管理: リソースグループを使用して、アプリケーションの構成情報や設定を一元管理でる。
・セキュリティ: リソースグループを使用して、関連するリソースに対して共通のセキュリティ設定を適用できる。
・バックアップと復元: リソースグループを使用して、アプリケーションのリソースを定期的にバックアップし、必要に応じて復元できる。
・コスト共通可視化
・リソースの履歴追跡共通化
リソースグループの単位は諸説ありますが、ライフサイクルが共通するリソースを同じリソースグループに含めることがベストのようです。
Activity Log
リソースに対して、どのようなアクションがあったかを記録するログです。
最上位はサブスクリプションで、リソースグループ以降の単位でも参照できます。
本記事で証跡ログと言っているのはこのActivity Logのことです。
証跡ログ調査手順
前提
まず Activity Log を調査する方法はいくつかあります。
その中で、なぜ今回の方法を取ったのかを説明します。
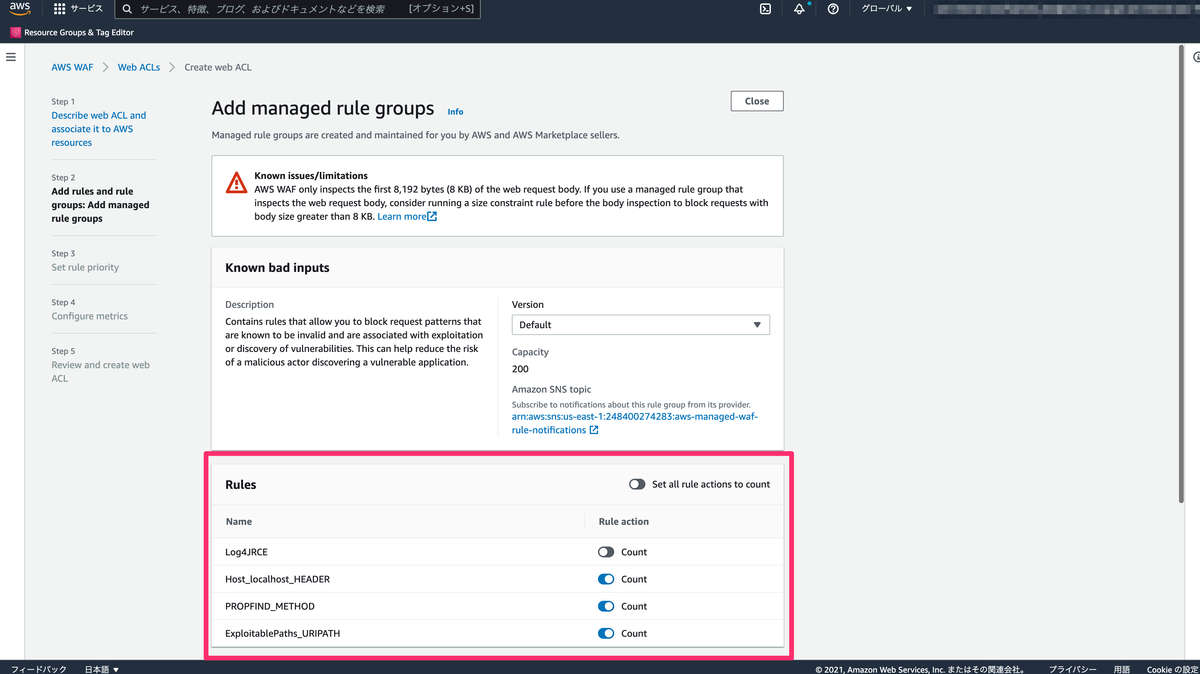
1. Activity Log の検索機能
Activity Log でも検索機能があるので、それを使って解析をすることはできます。
ですが、機能に限界があるのと、デフォルト保持期間は90日間なので、こちらは採用しません。

2. Log Analytics
Activity Log のエクスポートから診断設定を作成して、Log Analyticsへログをエクスポートします。
AWSで例えるなら、CloudWatch Logsで調査するイメージです。
Log Analytics ではKQLを使ってログを解析することができます。
Activity Logの量は膨大で、簡素な方法では Log Analytics へのエクスポートに料金が多くかかるので、こちらも採用しません。
ちなみに保持期間はデフォルトで2年間です。

3. [ Storage Blob 経由 ] Log Analytics
Activity Log のエクスポート設定で Blob コンテナにログを保管する設定をします。
Blob コンテナへのデータエクスポートは料金が安いです。
この Blob コンテナ内のログデータを任意で Data Factory などのサービスを使って Activity Log へデータを移すことができます。
任意の量のデータを Log Analytics で解析できますが、もっと簡素で良い方法をこの後紹介します。
4. [ Storage Blob 経由 ] Synapse Analytics
Synapse Analytics は Azure 上でビッグデータ分析を可能にするサービスです。
T-SQLを使ってデータ分析するサーバーは、サーバーレスを選択しましょう。
このサーバーレス SQL プール上で Blob コンテナ内のデータを参照できます。
参照するやり方は OPENROWSET 関数を使った参照と、外部データを定義するやり方の2種類ありますが、より簡素な前者を選択します。
手順
Synapse Analytics の サーバーレス SQL プール内で OPENROWSET 関数を使って、Blob コンテナに保管されたActivity Log を解析する方法を示します。
前提
もし、Blob コンテナのパブリックアクセスが拒否されている場合は注意点があります。
Synapse Analytics から Blob コンテナを参照するに当たって、実際に SQL を実行する組織ユーザーに対して、IAMで「ストレージ BLOB データ閲覧者」以上の権限が明示的についているかを確認してください。
「所有者」の権限がついていたとしても、ストレージ Blob 専用の権限がついている必要があり、そうでないと Blob を参照できません。

またストレージアカウントのネットワークで「すべてのネットワークから有効」が選択されているかも確認してください。
1. Synapse Analytics ワークスペースを作成
必要な情報を入力して作成しましょう。
その際、Synapse Analytics のログを出力する Data Lake Storage Gen2 を作成しましょう。
2. Synapse Studio にログイン
Synapse Analytics 専用のコンソールです。
概要メニューから、ワークスペースのWeb URL を選択します。
3. OPENROWSET 関数を使って Blob コンテナのデータを参照
Synapse Studio から、Develop メニューを選択し、SQL スクリプトを選択します。
接続は組み込み (サーバーレス SQL プール)、データベースの仕様は master が選択されていることを確認してください。

以下のような、SQLでBlobコンテナ内のActivity Logを検索することができます。
-- 5/18, 5/19のActivity Logを対象として、検索
WITH tmp_target_log
AS
(
SELECT *
FROM OPENROWSET(
BULK (
'https://xxx.blob.core.windows.net/insights-activity-logs/resourceId=/SUBSCRIPTIONS/AAAAAAA-2222-RRRR-9999-MMMMMMMMMMMM/y=2023/m=05/d=18/**',
'https://xxx.blob.core.windows.net/insights-activity-logs/resourceId=/SUBSCRIPTIONS/AAAAAAA-2222-RRRR-9999-MMMMMMMMMMMM/y=2023/m=05/d=19/**'
),
FORMAT = 'CSV',
FIELDTERMINATOR = '\0',
FIELDQUOTE = '0x0b',
ROWTERMINATOR = '0x0A'
) WITH (doc NVARCHAR(MAX)) AS rows
)
, target_log
AS
(
SELECT
-- 操作の名前の一部 操作の種類の詳細内訳 - "Write"/"Delete"/"Action"
JSON_VALUE(doc, '$.category') as 'category',
-- ログレベル
JSON_VALUE(doc, '$.level') as 'level',
-- イベント発生時間
JSON_VALUE(doc, '$.time') as 'time',
-- リソースID
JSON_VALUE(doc, '$.resourceId') as 'resourceId',
-- どのサービスに、どんなアクションをしたか
JSON_VALUE(doc, '$.operationName') as 'operationName',
-- アクションをした結果ステータス
JSON_VALUE(doc, '$.resultSignature') as 'resultSignature',
-- どのIPから呼び出されたか
JSON_VALUE(doc, '$.callerIpAddress') as 'callerIpAddress',
-- アクションの具体
JSON_VALUE(doc, '$.identity.authorization.action') as 'action',
-- アクションを実行した人の名前
-- Azureに組織メンバーとして登録されているユーザー名
JSON_VALUE(doc, '$.identity.claims.name') as 'name'
FROM tmp_target_log
)
------------------------------------
-- 以下で詳細な条件を絞ることもできます --
------------------------------------
-- , detail_log
-- AS
-- (
-- SELECT
-- *
-- FROM tmp_target_log
-- WHERE name = 'hogetaro'
-- )
------------------------------------
SELECT * FROM target_log;
Activity Log が Blob コンテナに保存されるときは json 形式で保存されます。
以下が json スキーマです。
以下に、クエリ内の中間テーブルである detail_log 内でのクエリ例を簡単に紹介します。
◇ 特定の誰かに絞る
SELECT
*
FROM tmp_target_log
WHERE LOWER('name') = LOWER('hogetaro');
◇ 特定のIPからのアクセスに絞る
SELECT
*
FROM tmp_target_log
WHERE callerIpAddress = 'xxx.xxx.xxx.xxx';
以上で手順は完了です。
まとめ
Azure OpenAI が利用開始されるようになってから、Azure 上でアプリケーションを開発する機会がより増えてくると思います。
少しでも参考になれば幸いです。