ECS内のインスタンスを自動ドレイニングするシステム構築 ~ ECS を使う上で外せないステータス 、ドレイニング~
はじめに
よくAWSに触れるものです。
AWSにはElastic Container Service(以下ECS)と呼ばれるフルマネージド型のコンテナオーケストレーションサービスがあります。
ECSはEC2インスタンス or Fargate上にコンテナをスケーラブルに配置、管理、監視できるサービスで、比較的扱いやすいサービスです。
そんなECSですがコンテナのライフサイクルやEC2を使う場合は配置、サービス(ECS特有の用語)によるタスクスケーリングなどはそれなりの知識が必要なのも事実です。
今回はそんなコンテナのライフサイクルに関連して、ドレイニングについて解説 & そのドレイニングを用いた安全なインスタンスの終了のさせ方を解説していきたいと思います。
ドレイニングについて
EC2のライフサイクルは複数あります。
こちらの公式ドキュメントに図が載っています。
これ以外にもECS側でのEC2のステータスがあります。それがDraining(ドレイニング)です。
Auto ScalingでScale Inすると、ドレイニング状態のインスタンスは、クラスター内でそのインスタンスが持つタスクを他のキャパシティに余裕があるインスタンス内に移動させます。
キャパシティはCPUとMemoryどちらとも収まる範囲で算出されます。
以下に図を示します。
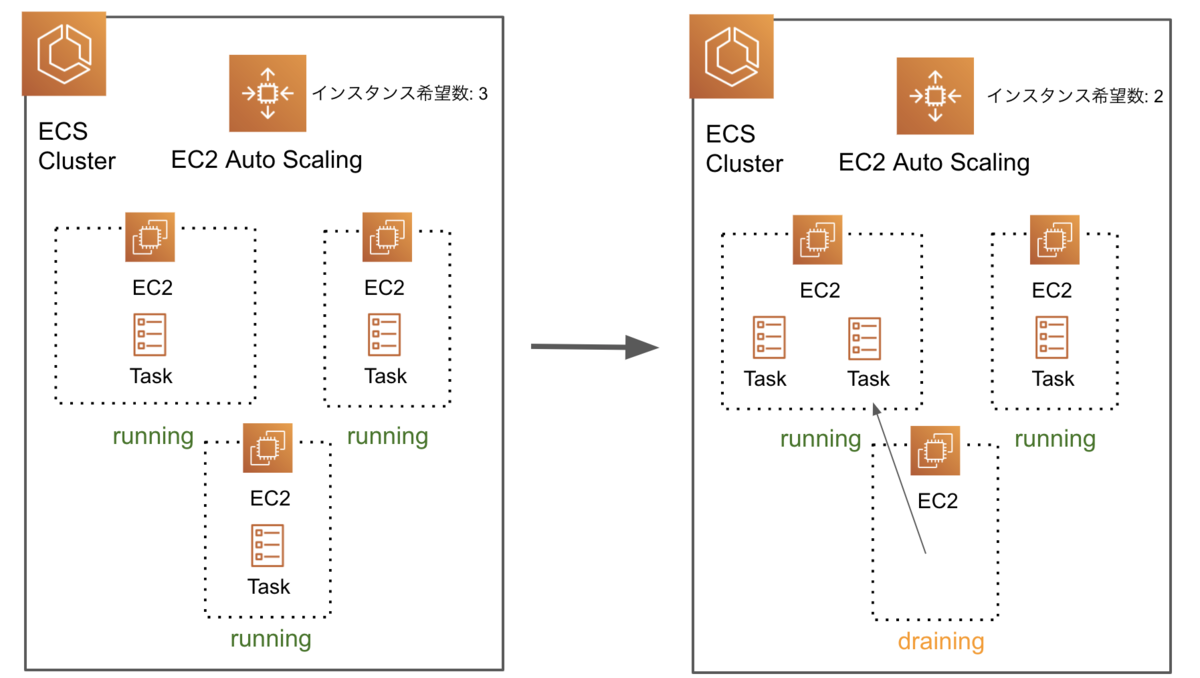
ステータスがStoppedにならずにタスクが移動するので、コネクションは途絶えずにダウンタイムは生じません。
一方、ドレイニング状態にないままAuto ScalingでScale Inすると、以下の図ではランダムに選ばれたインスタンスがStopped状態になり、内部のタスクは削除されます。

ドレイニング状態とは違い、タスクはそのまま削除されたのでコネクションは消えダウンタイムが生じる可能性があります。
ちなみに、Scale Inの際に削除を希望しないインスタンスを残す場合はAuto Scaliningの設定からインスタンスの削除保護を選択することで可能です。

Auto Scalingの設定画面からインスタンス管理を選択、削除を希望しないインスタンスを指定してスケールイン保護の設定を選択します。
これで指定したインスタンスはScale Inの対象から外れ削除されません。
以下からドレイニングの手段について解説します。
ドレイニング手段
手動
インスタンスを手動でドレイニングする方法はとても簡単です。
ECSコンソールからClusterを選択し、ECSインスタンスを選択してアクションからドレイニングを指定するだけです。

指定のインスタンスがドレイニング状態になったことが確認できたらインスタンスを削除してみましょう。

するとインスタンス内のタスクが他のキャパシティに余裕のあるインスタンスに移ることがわかります。
ただ手動のやり方だと、スケールインする際に毎回手動のオペレーションが増え、よきせぬスケールインには対応できません。
そのため今回は自動でドレイニングを走らせるシステムを構築したのでご紹介します。
自動
自動でドレイニングするシステムを構築します。
今回作成するリソースは以下です。
- SNS Topic
- SNS Subscription
- Lambda Function
- LambdaExecutionRole
- Lambda Permission
- Auto Scaling Lifecycle Hook
- Auto Scaling Lifecycle HookのIAM
流れとしては、Auto ScalingによってScale In →アクティビティ通知 -> SNS -> Lambda です。
ここでポイントとなるのはLifecycle Hookです。
Life cycle HookはAuto Scalingによってインスタンスが起動、削除される際にその実行を待ってカスタムアクションを追加することができます。
今回でいうと、Scale Inの際にインスタンスが削除されますが、それがHookとなり、指定のパラメータ通りの動きをします。
後ほど詳しく説明します。
以下が実際のテンプレートです。
Parameters: EcsClusterName: Type: String Description: Enter the target ECS cluster name. EcsInstanceAsg: Type: String Description: Enter the AutoScalingGroup name. Resources: SNSLambdaRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "autoscaling.amazonaws.com" Action: - "sts:AssumeRole" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AutoScalingNotificationAccessRole Path: "/" LambdaExecutionRole: Type: "AWS::IAM::Role" Properties: Policies: - PolicyName: "lambda-inline" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - autoscaling:CompleteLifecycleAction - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents - ecs:ListContainerInstances - ecs:DescribeContainerInstances - ecs:UpdateContainerInstancesState - sns:Publish Resource: "*" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "lambda.amazonaws.com" Action: - "sts:AssumeRole" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AutoScalingNotificationAccessRole Path: "/" ASGSNSTopic: Type: "AWS::SNS::Topic" Properties: Subscription: - Endpoint: Fn::GetAtt: - "LambdaFunctionForASG" - "Arn" Protocol: "lambda" DependsOn: "LambdaFunctionForASG" LambdaFunctionForASG: Type: "AWS::Lambda::Function" Properties: Description: Gracefully drain ECS tasks from EC2 instances before the instances are terminated by autoscaling. Handler: index.lambda_handler Role: !GetAtt LambdaExecutionRole.Arn Runtime: python3.6 MemorySize: 128 Timeout: 60 Code: ZipFile: !Sub | import xxx import xxx <ここにpythonの処理を書いていきます> LambdaInvokePermission: Type: "AWS::Lambda::Permission" Properties: FunctionName: !Ref LambdaFunctionForASG Action: lambda:InvokeFunction Principal: "sns.amazonaws.com" SourceArn: !Ref ASGSNSTopic LambdaSubscriptionToSNSTopic: Type: AWS::SNS::Subscription Properties: Endpoint: Fn::GetAtt: - "LambdaFunctionForASG" - "Arn" Protocol: 'lambda' TopicArn: !Ref ASGSNSTopic ASGTerminateHook: Type: "AWS::AutoScaling::LifecycleHook" Properties: AutoScalingGroupName: !Ref EcsInstanceAsg DefaultResult: "ABANDON" HeartbeatTimeout: "900" LifecycleTransition: "autoscaling:EC2_INSTANCE_TERMINATING" NotificationTargetARN: !Ref ASGSNSTopic RoleARN: Fn::GetAtt: - "SNSLambdaRole" - "Arn" DependsOn: "ASGSNSTopic"
上記でlifecycle HookではHeartbeatTimeoutとDefaultResultの設定が肝です。
HeartbeatTimeoutはLifecycle Hookが動いてから経過した時間を指し、その後DefaultResultを実行します。
なので上記ではAuto ScalingでScale Inが走り、インスタンス削除処理がHookになり、そのHookが起こってから900秒立ってもLifecycle Hookが完了しないならABANDON、つまりインスタンスは強制的に削除されます。
このHookがないと、例えば、他のインスタンスにタスクが移るときにポート被りやリソース不足で移動できないとずっとインスタンスがドレイニング状態のままインスタンスが残り続けることになります。
なので、一定期間立ったら強制的に削除するようにして、強制終了したことをslackなどに通知するといいでしょう。
次にLambdaにおける処理を見てみましょう。
import json import time import boto3 CLUSTER = '${EcsClusterName}' REGION = '${AWS::Region}' ECS = boto3.client('ecs', region_name=REGION) ASG = boto3.client('autoscaling', region_name=REGION) SNS = boto3.client('sns', region_name=REGION) def find_ecs_instance_info(instance_id): paginator = ECS.get_paginator('list_container_instances') for list_resp in paginator.paginate(cluster=CLUSTER): arns = list_resp['containerInstanceArns'] desc_resp = ECS.describe_container_instances(cluster=CLUSTER,containerInstances=arns) for container_instance in desc_resp['containerInstances']: if container_instance['ec2InstanceId'] != instance_id: continue print('Found instance: id=%s, arn=%s, status=%s, runningTasksCount=%s' % (instance_id, container_instance['containerInstanceArn'], container_instance['status'], container_instance['runningTasksCount'])) return (container_instance['containerInstanceArn'], container_instance['status'], container_instance['runningTasksCount']) return None, None, 0 def instance_has_running_tasks(instance_id): (instance_arn, container_status, running_tasks) = find_ecs_instance_info(instance_id) if instance_arn is None: print('Could not find instance ID %s. Letting autoscaling kill the instance.' % (instance_id)) return False if container_status != 'DRAINING': print('Setting container instance %s (%s) to DRAINING' % (instance_id, instance_arn)) ECS.update_container_instances_state(cluster=CLUSTER, containerInstances=[instance_arn], status='DRAINING') return running_tasks > 0 def lambda_handler(event, context): msg = json.loads(event['Records'][0]['Sns']['Message']) if 'LifecycleTransition' not in msg.keys() or \ msg['LifecycleTransition'].find('autoscaling:EC2_INSTANCE_TERMINATING') == -1: print('Exiting since the lifecycle transition is not EC2_INSTANCE_TERMINATING.') return if instance_has_running_tasks(msg['EC2InstanceId']): print('Tasks are still running on instance %s; posting msg to SNS topic %s' % (msg['EC2InstanceId'], event['Records'][0]['Sns']['TopicArn'])) time.sleep(5) sns_resp = SNS.publish(TopicArn=event['Records'][0]['Sns']['TopicArn'], Message=json.dumps(msg), Subject='Publishing SNS msg to invoke Lambda again.') print('Posted msg %s to SNS topic.' % (sns_resp['MessageId'])) else: print('No tasks are running on instance %s; setting lifecycle to complete' % (msg['EC2InstanceId'])) ASG.complete_lifecycle_action(LifecycleHookName=msg['LifecycleHookName'], AutoScalingGroupName=msg['AutoScalingGroupName'], LifecycleActionResult='CONTINUE', InstanceId=msg['EC2InstanceId'])
find_ecs_instance_infoはECS上でのインスタンスの状態を検知してくれます。
ECS上のインスタンスすべての情報を取り、そのjson値からstatusを返します。
instance_has_running_tasksはインスタンス内にコンテナが走っている場合はインスタンスのステータスをドレイニング状態にします。
最後にlambda_handlerの中でmainの処理を実行します。
インスタンス内のSNS経由のメッセージで情報を受け取りインスタンス内のコンテナが0になったときに待機状態にあったlifecycle Hookを完了します。
以上のテンプレートをCloudformationで流すことで自動ドレイニングシステムは作成されます。
1つ手作業があり、Scale Inが走った際にSNSを通してLambda実行するためのアクティビティ通知を設定しないといけません。

AWSコンソールでAuto Scaling Groupを選択して、アクティビティ通知の作成を選択、「終了」アクションが起こったときに指定のSNSに通知するように設定します。
以上でシステムの構築は完了です。
実際にScale Inをしてみて、任意のインスタンスがドレイニング状態になり安全にインスタンスが削除されるか確認しましょう。
終わりに
今回はECSのインスタンスのライフサイクルに関することを書きました。
ECSのインスタンスリソース調整やタスク配置は奥が深いので、今度はそちらについても書こうかなと思います。